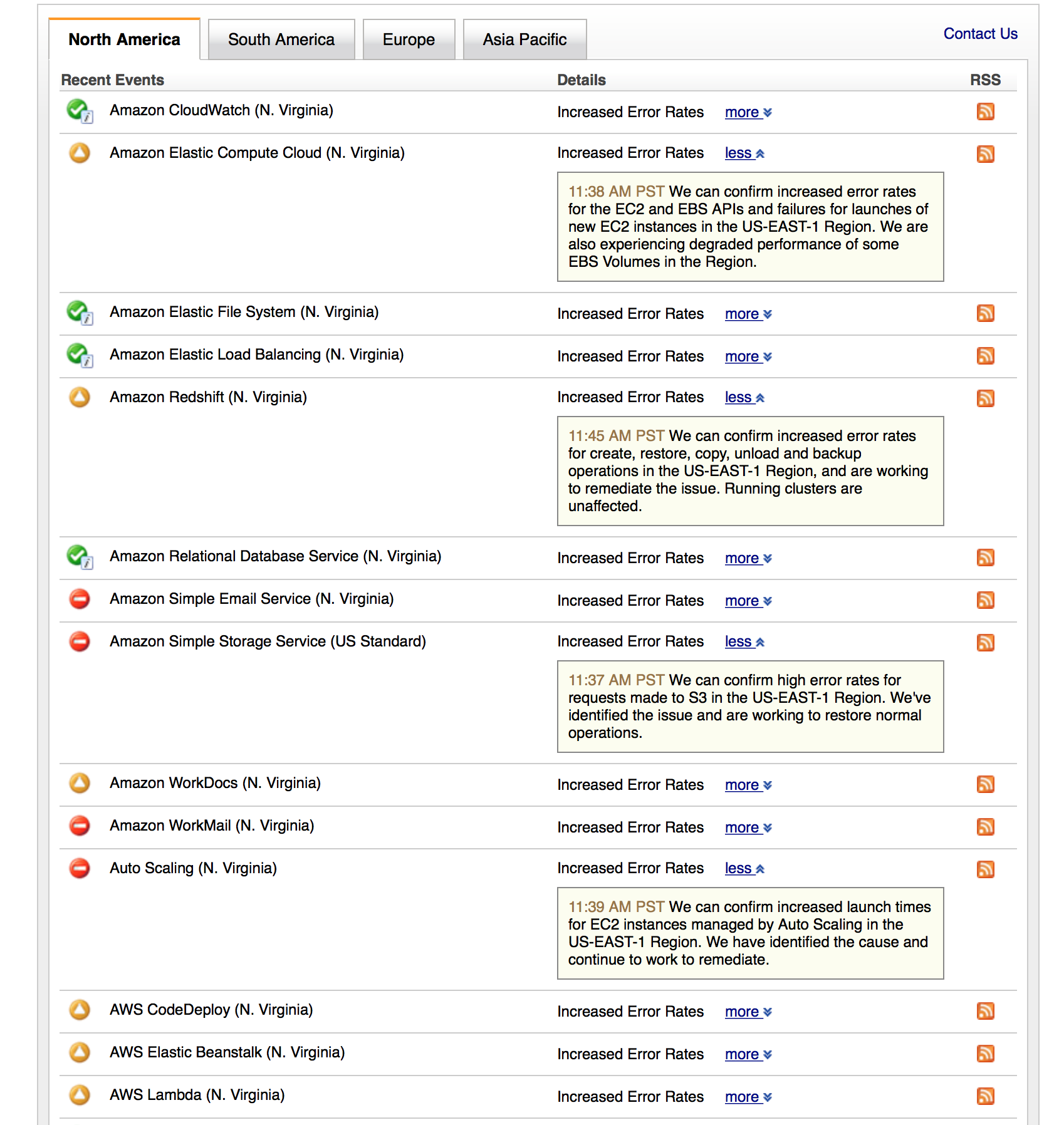
 Today AWS S3 is down in the US-EAST-1 region – taking many other services down along with it.
Today AWS S3 is down in the US-EAST-1 region – taking many other services down along with it.
Large swaths of the internet are impacted including 1 or 2 of my non-critical sites/applications. However, my mission critical sites/applications are fine. Why? Because if they are mission critical they should never be susceptible to a failure of a single physical location… period.
You could have stayed up today – here are some examples of how:
- S3 Static Site Hosting – Distribute the site with Cloudfront with (at least) the standard 24 hour TTL.
- S3 Storage – either distribute static content with Cloudfront or replicate your bucket(s) to another region.
- S3 Streaming Data – write your streams to either buffer when the region is not available or fail to another region. Data processing (lambda, etc) should continue from either region in the fail over scenario.
- EC2 & Autoscaling – Replicate your snapshots and AMIs across regions. Run services in multiple regions or be prepared to fail over to an alternate region.
- Big Data workloads:
- Be prepared to buffer all writes locally until the services comes back up.
- This is equally relevant to network partitions.
Last, but not least, test these regularly. Make sure you know what happens and how your code behaves.
This list is – by no means – comprehensive, but it is a great starting point for most services.
My meta-recommendation is to always be prepared for service interruptions at every level of your architecture. You may choose not to have a 100% redundancy – but do that intentionally and transparently (with business stakeholders). You’ll save yourself a lot of panic on a day like today.